












")

 ABBYY Recognition Server предназначен для потокового ввода документов в компаниях и организации электронного архива в компаниях.
ABBYY Recognition Server предназначен для потокового ввода документов в компаниях и организации электронного архива в компаниях.
Решение позволяет оцифровывать входящие документы, подготавливать их для хранения в электронном архиве или редактирования, передачи в хранилища или в общие папки, а также для непосредственной рассылки персоналу. С помощью поисковых систем можно индексировать изображения, сканировать документы и фотографии, которые хранятся в системах документооборота и на компьютерах пользователей.
ABBYY Recognition Server автоматизирован, легко масштабируется и отличается высокой производительностью, простотой администрирования и использования.
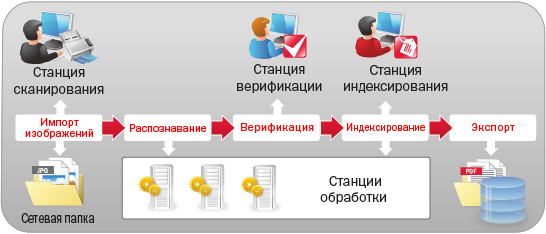
Принцип работы ABBYY Recognition Server
Работа системы:
- Документы сканируются с помощью станции сканирования или поступают на обработку через «горячую» папку в локальной сети и по электронной почте;
- Программа автоматически выполняет распознавание изображений и поиск штрихкодов;
- При необходимости можно задействовать верификацию и визуально проверить результаты распознавания на станции верификации;
- Поток распознанных изображений разделяется на документы. Программа позволяет определить тип каждого документа и присвоить ему соответствующие атрибуты;
- Документы экспортируются в нужном формате (сохраняются в папку, загружаются в СЭД, отправляются по электронной почте и т.д.).
Этапы обработки документов:
Импорт изображений и предварительная обработка
Различные форматы файлов:
- Конвертация изображений из форматов: JPEG, TIFF, BMP, PDF, DjVu и другие.
Импорт изображений из различных источников:
- Импорт из локальной или сетевой папки: поддержаны входящие папки со сложной структурой (со вложенными подпапками), при экспорте программа автоматически повторяет структуру входящей папки.
- Импорт вложений из писем, присланных по электронной почте. Пользователи могут посылать изображения на распознавание как из своей почтовой программы, так и непосредственно с сетевых сканеров и МФУ.
- Импорт через станцию сканирования. Документы могут поступать с разных станций сканирования разными пакетами.
Предварительная обработка:
- Автоматическое определение ориентации;
- Исправление перекосов;
- Разделение сдвоенных книжных страниц.
Распознавание и конвертация
Высокое качество распознавания и восстановления оформления документа:
- Поддержка 191 языка распознавания печатного текста, включая языки на основе латинского, греческого, тайского, армянского и кириллического алфавитов, а также японский, корейский, китайский и тайский языки.
- Распознавание многоязычных документов.
- Режим быстрого распознавания увеличивает скорость обработки изображений хорошего качества в 2-2,5 раза.
- Поддержано распознавание различных типов текста: типографская печать, печатная машинка, матричный принтер, MICR (E13B), OCR-A, OCR-B.
Распознавание штрихкодов:
- Поддержано распознавание наиболее популярных одномерных и двумерных штрихкодов.
- Автоматически идентифицируются и распознаются штрихкоды, расположенные на странице под любым углом к горизонтали.
Контроль качества распознавания:
- Установка порога качества распознавания изображений, основанная на допустимом количестве неуверенно распознанных символов на страницу.
Преобразование PDF-файлов
-
Определение текстового слоя и его целостности для обеспечения более быстрого и качественного преобразования PDF-файлов.
- В создаваемых PDF-файлах сохраняются метаданные документа (название, автор, тема, ключевые слова) и восстанавливаются гиперссылки внутри документа.
- Поддержаны алгоритмы шифрования и другие средства разграничения доступа: сохранение результатов распознавания в PDF-файл, защищенный паролем.
Обработка заданий
Разделение и сборка документов:
- Разделение документов в потоке по пустым листам, листам с разделительным штрихкодом, по фиксированному количеству страниц в документе.
- Возможна сборка одностраничных изображений из каждой обрабатываемой подпапки в отдельный файл.
Многопроцессорная работа:
- Запуск нескольких параллельных процессов распознавания позволяет эффективно задействовать ресурсы многопроцессорной системы.
- Предусмотрена масштабируемость на несколько компьютеров в локальной сети: можно легко расширять мощность системы, увеличивая количество станций обработки. Подключение дополнительных станций через консоль администрирования занимает всего несколько минут.
- Задание расписания для отдельных станций обработки или групп станций дает возможность управлять загрузкой вычислительных мощностей в течение рабочего дня или недели.
Равномерная загрузка:
- Менеджер сервера автоматически распределяет задания между станциями обработки, выравнивая нагрузку между процессорами.
- Менеджер сервера самостоятельно разделяет многостраничный документ на части и отправляет каждую из частей на свободную станцию обработки. Затем все части документа снова будут собраны в одно задание. Таким образом, распознавание/конвертация нескольких частей одного документа происходит одновременно.
Отказоустойчивость:
- Периодическая проверка работоспособности станций.
- Автоматическое восстановление связи со станцией после временного сбоя в работе станции.
- Автоматический запуск менеджера сервера после перезагрузки операционной системы.
- Автоматическое возвращение задания в очередь или перенаправление задания на другую доступную станцию в случае сбоя в работе станции.
Верификация
Станция верификации позволяет оператору проверять, правильно ли была проанализирована страница, создавать и редактировать блоки, проверять неуверенно распознанные символы, а также редактировать распознанный текст.
После верификации и устранения ошибок страница будет отправлена на дальнейшую обработку или проэкспортирована. При неудовлетворительных результатах распознавания оператор станции верификации может отправить страницу на повторную обработку.
Индексирование
Индексирование позволяет присваивать атрибуты распознанным документам: «дата», «номер документа», «краткое содержание» и другие. Индексирование документов может быть осуществлено:
-
автоматически при помощи скрипта;
-
вручную на станции индексирования.
Экспорт результатов
- Публикация документов в локальную или сетевую папку с сохранением структуры вложенных подпапок.
- Публикация документов в библиотеки Microsoft Office SharePoint Server.
- Отправка распознанных документов получателям по электронной почте. Документ может быть отправлен на тот же адрес, с которого поступило изображение для распознавания, или на любой другой адрес, указанный в задании.
- Правила для формирования имени выходного файла и папки, в которую его следует сохранить. Имена файла и папки могут быть сформированы с использованием значения разделительного штрихкода, даты и времени поступления документа и т.д.




